
AlwaysOn Availability Group (AG) is one of my favorite features in SQL Server and is worth considering when using SQL server 2012 or greater. One of the nicest features in AlwaysOn AG is that in a single subnet environment it can be totally transparent to your application. What this means is that for older legacy applications, this will still work. The application will still only point at a single connection string and will have no knowledge of the underlying systems. In multi-subnet configurations, you will either need to make sure that MultiSubnetFailover=True in the connection string or modify the RegisterAllProvidersIP Windows property. More information on both of these items can be found at https://www.sqlhammer.com/how-to-configure-sql-server-2012-alwayson-part-7-of-7/ and http://blogs.msdn.com/b/sambetts/archive/2014/02/04/multi-subnet-clustered-sql-registerallprovidersip-sharepoint-2013.aspx This blog will cover the benefits of AlwaysOn and present a case for why you should consider it in your environment.
Starting with SQL 2016 AlwaysOn AG comes in 2 flavors, Basic and Enhanced. Using SQL Server Standard edition in 2016 a basic Availability Group replaces the database mirroring feature. There are limits to a basic Availability Group, but it can serve as a HA solution. Limitations for basic Availability Group are:
- Limit of two replicas (primary and secondary).
- No read access on secondary replica.
- No backups on secondary replica.
- No integrity checks on secondary replicas.
- No support for replicas hosted on servers running a version of SQL Server prior to SQL Server 2016 Community Technology Preview 3 (CTP3).
- Basic Availability Groups cannot be upgraded to advanced Availability Groups. If you upgrade SQL to Enterprise edition, the Availability Group must be dropped and recreated before advanced Availability Groups can be used.
- Basic Availability Groups are only supported for Standard Edition servers.
- Basic Availability Groups cannot be part of a distributed Availability Group.
- Only a single database per Availability Group is allowed
Enhanced Availability Groups come with Enterprise edition of SQL Server. In an enhanced Availability Group, you have none of the above limitations. In addition to not having the limits imposed on a basic availability group, you also get:
- Domain Independent Availability Groups (https://cloudblogs.microsoft.com/sqlserver/2015/12/15/enhanced-always-on-availability-groups-in-sql-server-2016/)
- Increased number of Auto-Failover targets (Primary + 2 starting in 2016) (https://blogs.technet.microsoft.com/dataplatform/2016/11/07/sql-server-2016-ha-series-3-auto-failover-targets-pt1/)
- Enhanced Log Replication throughput and redo speed (https://blogs.msdn.microsoft.com/sql_server_team/sql-server-20162017-availability-group-secondary-replica-redo-model-and-performance/)
- Support for Group-Managed Service accounts (https://docs.microsoft.com/en-us/windows-server/security/group-managed-service-accounts/group-managed-service-accounts-overview)
- Support for Distributed Transactions (DTC) (https://blogs.technet.microsoft.com/dataplatform/2016/01/25/sql-server-2016-dtc-support-in-availability-groups/)
- Direct seeding of new database replicas (https://www.sqlshack.com/sql-server-2016-always-availability-group-direct-seeding/)
- Read-Only Routing (https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/configure-read-only-routing-for-an-availability-group-sql-server?view=sql-server-2016)
There are a lot of similarities between the 2 different flavors of AlwaysOn AG. Unlike a traditional shared storage SQL cluster, AlwaysOn AG does not share the same underlying storage, and both nodes will have their own services up and running. This eliminates the single point of failure caused by shared disk and reduces the amount of time needed to failover in case of an outage. Keep in mind that if both nodes are using the same SAN, you will want them to be on different LUN’s, however, for a true HA solution it is recommended to have the storage on separate SANs as well. Depending on the size and activity in your databases the downtime could be limited to a single packet loss during failover.
When configuring AlwaysOn AG we can choose to make the replicas readable (readable secondaries are only available in Enterprise edition) if the data should be synchronous or asynchronous and if we want to allow for automatic failovers. A readable secondary means that data can be read from that replica but no modifications to the data can be made on that replica. A replica in synchronous commit ensures that all transactions are written to the primary and all synchronous replicas before the transaction is completed and the application is notified. Asynchronous replicas are not guaranteed to be applied before notifying the application that the transaction is complete.
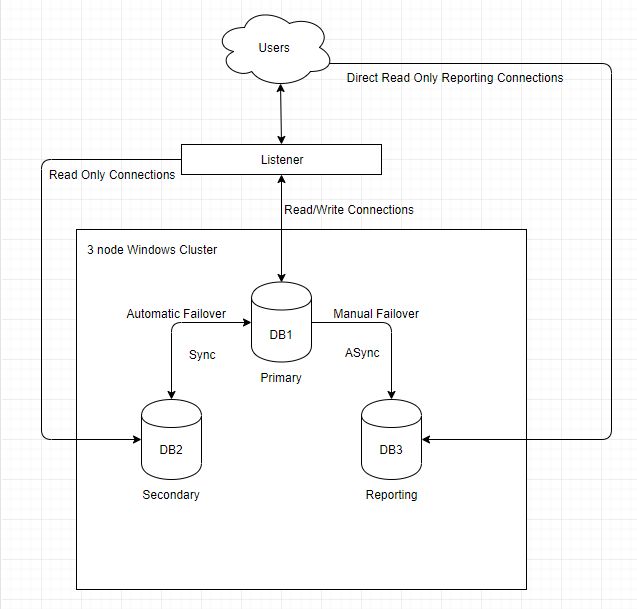
In the diagram above we have a 3 node cluster. A primary replica that serves as a read/write replica and will handle any data modifications. A synchronous secondary node that is enabled as a readable secondary, and a 3rd asynchronous readable secondary that will be used for reporting. This 3rd replica could have been set to synchronous and be automatically failed over to if need be, but most of the time a 3rd node is either in a DR site or for reporting purposes. While AlwaysOn AG still uses the underlying Windows Server Failover Clustering (WSFC) engine. The windows server failover clustering engine is used by AlwaysOn AG for:
- Monitoring and managing the current roles of the availability replicas that belong to a given Availability Group and to determine how a failover event affects the availability replicas.
- quorum for AlwaysOn Availability Groups is based on all nodes in the WSFC cluster regardless of whether a given cluster node hosts any availability replicas.
Outside of the above uses, there are no more similarities between AlwaysOn AG and a traditional SQL cluster.
This implementation of AlwaysOn AG give us a high availability SQL cluster and will allow us to offload read-only requests to the secondary node via read-only routing. Read-Only routing allows us to create routing tables so that connections that specify that they are only doing a read request will be sent to the secondary node. This can help to alleviate blocking, disk I/O, and CPU issues. If your application is AlwaysOn AG aware, there is a good chance that it will support the read-only connection string. If you develop your own applications, then you can phase in the read-only connections over time with normal application updates providing that your secondary replicas are licensed (more on this in the drawbacks section).
When implementing AlwaysOn AG you will create Availability Groups, availability groups allow you to group databases into like applications (only in Enterprise edition). If your database server supports multiple applications, you could create multiple Availability Groups which will house the database(s) required for each application. This will allow you to fail the entire application over to a secondary node for maintenance easily unlike in mirroring where each database has to be failed over individually or like a traditional shared storage cluster where the entire instance would have to failover. It also allows you to set different options for different applications and even will allow for application A to be primary on server A and application B to be primary on Server B while still participating in AlwaysOn AG.
Failing over can be done either manually or automatically. In a synchronous commit setup, automatic failover is supported and will change the primary server when it detects that the current primary is no longer healthy. This is determined by the sp_server_diagnostics procedure that is executed against the primary server. The default failure condition level is 3 and can be adjusted to accommodate less severe issues. More information about failover conditions can be found at https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/flexible-automatic-failover-policy-availability-group?view=sql-server-2017
The Listener in the diagram above acts as a traffic cop and is the interface that the applications connect to. It will keep track of which node is the primary node and route connections appropriately. Simply changing the connection string to the listener is all that is needed from the application side to work with AlwaysOn AG. Keep in mind that the more complex your environment the more care should be taken. It is possible to have replicas spanning multiple subnets and sites, which makes the setup more complex but still achievable. In these more complicated cases, driver versions must be checked to determine if they will support the multi-subnet failover options. An incorrect configuration can extend the time it takes for clients to recover in the case of a failover.
Referring back to the image above we still have a 3rd asynchronous replica sitting out there for reporting. In the scenario as depicted above, we would not point the reporting applications at the listener, but at the machine that is hosting this replica. This is because we want the asynchronous node to be used for reporting purposes, not the secondary node that the application may be used for read-only requests, while it would be possible to set this 3rd node up a synchronous commit and have SQL load balance the read-only requests that may not be ideal in all situations. This will allow us real-time reporting without affecting the application and can in many cases remove the need for replication if it is only being used for reporting. Even though the reporting application would not be connecting via the listener, we would still have the ability to manually failover to this node in case the need arose.
Benefits of AlwaysOn AG
Automatic or Manual Failover: You can set the failover option at the Availability Group level. Automatic failover must have replica’s in synchronous commit mode. Replicas using an asynchronous commit cannot be failed over automatically.
Automatic Page Repair: After certain types of errors corrupt a page, making it unreadable, an availability replica (primary or secondary) attempts to automatically recover the page. The replica that cannot read the page requests a fresh copy of the page from another replica. If this request succeeds, the unreadable page is replaced by the readable copy, and this usually resolves the error. It is important to note that automatic page repair differs from DBCC repair. All of the data is preserved by an automatic page repair. In contrast, correcting errors by using the DBCC REPAIR_ALLOW_DATA_LOSS option might require that some pages, and therefore data, be deleted.
Active use of Secondaries: The databases on your secondary replicas can be configured to be read from allowing for read-only routing and real-time reporting. This can help to alleviate blocking, I/O contention, and high CPU issues. You are also able to do some maintenance tasks on the secondary replicas like log backups, Copy Only full backups and integrity checks. It is still recommended to run a physical_only integrity check on the primary at a minimum.
Simpler SQL Server Installations: SQL server can participate in AlwaysOn AG without installing the special Clustered version of SQL server. Further, once the underlying windows failover clustering is setup, management of the AlwaysOn AG environment is done in Management Studio i.e manual failovers (All failovers should be done via SMSS and not inside of WCFS), verifying the health of your AG(s), etc.
Offloaded Maintenance Tasks: Log backups can be taken from a secondary replica as well as copy only full backups (Differential backups must be taken on the primary). Integrity checks can also be run from a secondary replica, although it is advised to still run an integrity check with at least a physical_only flag on the primary. (If doing maintenance tasks or reading from a secondary replica the replicas will need to be licensed).
Works with existing features: AlwaysOn will continue to work with Transparent Data Encryption (TDE), Replication, Compression, and other features.
Reduced Maintenance Windows: Patching is something that has always been difficult with SQL server. You cannot pre-stage a patch as it will inevitably, restart the service on you. This means that you have to endure the entire patch time when applying the patch. With AlwaysOn AG you can patch the secondary nodes, and then do a planned failover and patch the primary while the application remains available as long as all AGs are on one server and not load balanced.
Easier Upgrades and Patching: Upgrading to a newer version of SQL is very simple with AlwaysOn AG. After you ensure that all of your databases are running on node 1, you can upgrade/patch your secondary. Once the secondary is in the state you desire, you fail all of your Availability Groups over to node2 and then do the upgrade/patching on node1. This allows you to patch upgrade with minimal downtime to your users. You can also use this method to migrate to a new machine or even a new version of SQL, although these would require changes in the Failover Cluster, it is a very viable approach for migrations. Keep in mind that you would still have to migrate objects that are not contained in a database that is a part of an Availability Group, like logins and jobs. Be advised that once you failover to a newer version, you cannot fail back until the original primary server is also upgraded.
Drawbacks of AlwaysOn AG
Some of the items listed below may not really be considered a drawback, but in some cases, they could become problematic so they are listed here.
Licensing: Prior to SQL 2016, AlwaysOn AG required Enterprise edition. While 2016 does allow for basic availability groups in Standard edition, there are many limitations.
Server Settings: System databases cannot be a part of an Availability Group. This means that server level objects (logins, Jobs, configuration settings, SSIS packages stored in msdb. . .) will need to be applied to all replicas separately. Care must be taken when making a system level change to make sure it is applied across all replicas.
Database Level Constraints:
-
- Databases must be read-write
- Databases must be in multi-user mode
- Databases can’t use the AUTO_CLOSE feature (this is not a drawback)
- Databases must use the full recovery model
-Be sure to set up your log backups!
- A database can only be in a single Availability Group, and that database can’t be configured to use database mirroring.
Worker Threads: Secondary replicas use more worker threads than the primary node.
In a very busy server, or an Availability Group with many databases (100+ usually) you could experience worker thread starvation on the secondary node which can delay transactions on the primary node.
Not a True DR Solution: While many people will commonly refer to AlwaysOn AG as an HA/DR solution, it does not provide a true DR solution but more of a hybrid solution. This is because transactions are always implemented in real time or near real time. It does not allow for a delayed execution of commands to protect against accidental changes. If malicious user drops a table, that change is passed on to the other nodes and you are still facing recovery options. In a true DR solution, there is a delay in executing the commands to allow you to stop the malicious command from being executed so you can recover without having to go to backups. The reason I see this as a hybrid solution is that it does allow for automatic failovers even to a DR site, and can be used in conjunction with other solutions like log shipping and replication.
While there are some potential pitfalls, AlwaysOn AG is a wonderful technology and is ready for mainstream implementation. Proper planning and testing, combined with a good understanding of the limitations and constraints will make for a highly available robust environment. I know that there are many more features and benefits of AlwaysOn AG that I did not cover, however, I hope that this helps to bring some clarity to AlwaysOn AG.