
You can also check out the Recorded Webinar.
You may see events in your error logs reporting transient connection failures between cluster nodes or AlwayOn. You may observe high Asynch_Network_IO in [sys].[dm_os_wait_stats]. And you may have even brought it to the attention of your Network folks, only to be sent away being told that the network is “fine” leaving you at a loss.
Transient network issues can arise from a variety of sources. They wreak havoc on the stability of Window Server Failover Clustering (WSFC) and SQL Server AlwaysOn.
WSFC, the Resource Host, and SQL Server, all synchronize with each other via Remote Procedure Call, Shared Memory, and TSQL Commands.
While WSFC could detect Quorum loss, the resource DLL might detect issues with AlwaysOn.
The NIC might be misconfigured or not configured at all for SQL Server resulting in periods of congestion at the NIC, and ultimately dropped packets which appear as a network hiccup. If the “hiccup” lasts long enough, a failure of the node is assumed and unnecessary failover is initiated.
In most cases, this ballet of communication between services provides extremely reliable failover detection. However, the default NIC configuration and sensitivity levels among the different processes may be too aggressive or inadequate for your environment. Further tuning must be performed in order to achieve the desired ratio of stability vs. failover detection.
It is important to address any misconfigurations before tuning the sensitivity related settings. Oftentimes connectivity issues are due to simple misconfiguration(s) and the out of the box sensitivity values are perfectly adequate.
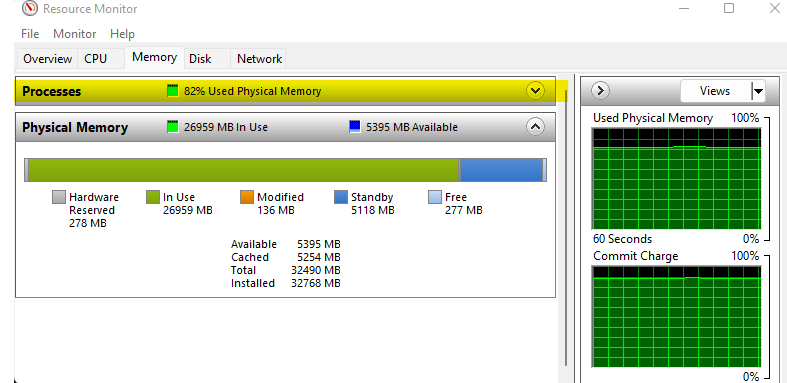
First, you want to be sure SQL Server isn’t overrunning Windows memory management – Check task manager and make sure memory utilization is between 77-82%. Regardless of the number of GB available to Windows Server, when utilization approaches 90% Windows Memory Management starts to kick in dramatically affecting the entire server performance. Memory utilization on your SQL Server should be no higher than 82%:
Now let’s turn our attention to the NIC/vNIC configuration. SQL Server requires Receive Side Scaling (RSS) to be ENABLED for maximum performance and reliability. RSS must be enabled in Windows AND on the NIC/vNIC.
Verify that Windows is enabled for RSS:
#To Verify RSS Enabled in Windows (CMD as Administrator):
netsh int tcp show global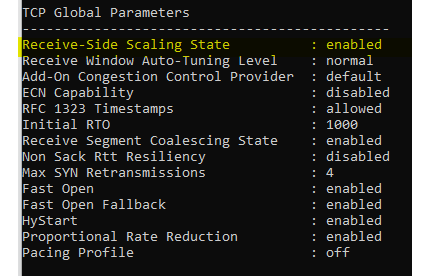
Once we know that Windows is ready for RSS, we can take a look at the NIC/vNIC configuration.
#To Verify RSS Enabled on the Nic (PoSh as Administrator)
Get-NetAdapter | Where-Object { $_.InterfaceDescription -like '*' } |`
Get-NetAdapterAdvancedProperty |`
Format-Table -AutoSize
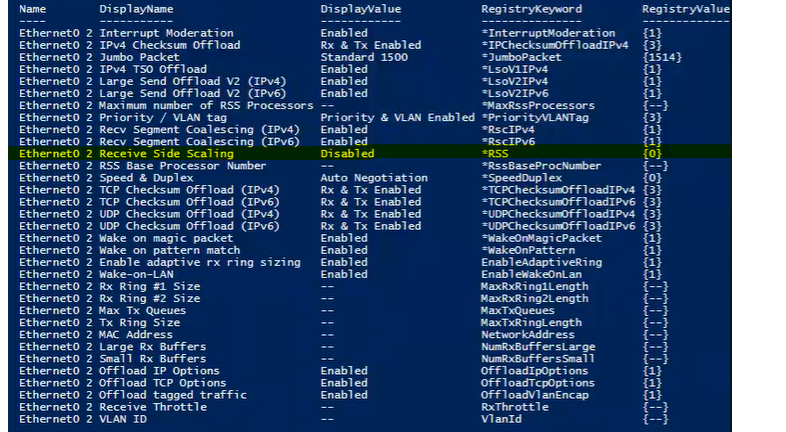
There are several settings missing from the above adapter (denoted with “–”).Besides RSS being disabled, you can see from the above that Send/Receive Buffer and related Ring Sizes have not been configured. It is important to verify the vNic settings have not changed each time after updating VMWare Tools on a guest.
#To View RSS CPU Matrix (PoSh as Administrator)
Get-NetAdapterRss -Name "*"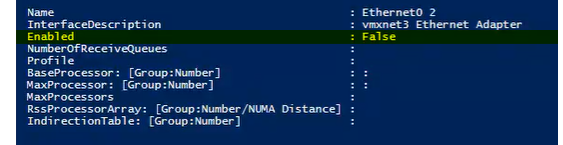
Now that we have verified that Windows Memory Management is happy, and RSS is being utilized, if Cluster / AlwaysOn stability is still a problem we can turn our attention to the various Cluster and AlwaysOn sensitivity parameters we have at our disposal.
Properties that can be adjusted to make the nodes more resilient:

You can query the above setting on your cluster using the following:
#display current cluster properties (the top six rows above – PoSh as Administrator)
Get-Cluster | fl CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay , SameSubnetThreshold#display current AG role properties (the last row above – PoSh as Administrator)
Get-ClusterResource | Get-ClusterParameter HealthCheckTimeout, LeaseTimeout –OR via TSQL in SSMS:
select ag.name,
arcn.replica_server_name,
arcn.node_name,
ars.role,
ars.role_desc,
ars.connected_state_desc,
ars.synchronization_health_desc,
ar.availability_mode_desc,
ag.failure_condition_level,
ar.failover_mode_desc,
ar.session_timeout
from sys.availability_replicas ar with (nolock)
inner join sys.dm_hadr_availability_replica_states ars with (nolock)
on ars.replica_id = ar.replica_id
and ars.group_id = ar.group_id
inner join sys.availability_groups ag with (nolock)
on ag.group_id = ar.group_id
inner join sys.dm_hadr_availability_replica_cluster_nodes arcn with (nolock)
on arcn.group_name = ag.name
and arcn.replica_server_name = ar.replica_server_name
When adjusting sensitivity, you have to first know whether your cluster nodes live in different subnets. If so, you would focus your attention on the Cross Subnet values. If not, then you would want to adjust the Same Subnet values.
In the following example, we increase the allowable same-subnet network hiccup / downtime from 10 to 20 seconds, and the allowable cross-subnet hiccup downtime from 20 to 40 seconds:
- LeaseTimeout – change from 20000 to 40000 (40 seconds)
- HealthCheckTimeout – change from 30000 to 60000 (60 seconds)
- Cluster Sensitivity
- SameSubnetThreshold – change from 10 to 20
- CrossSubnetThreshold – change from 20 to 40
or: - SameSubnetDelay – change from 1000 to 2000
- CrossSubnetDelay – change from 2000 to 4000
- Session Timeout – change from 10 to 20 seconds
Note: When increasing the (Delay * Threshold) product to make the cluster timeout more tolerant, it is more effective to first increase the delay value(s) before increasing the threshold(s). By increasing the delay, the time between each heartbeat is increased. More time between heartbeats, allows for more time for transient network issues to resolve themselves and decrease network congestion relative to sending more heartbeats in the same period. **If you do decide to increase the SameSubnetThreshold or CrossSubnetThreshold values, it is recommended to increase RouteHistoryLength to be twice that of the CrossSubnetThreshold (which is always equal to or larger than the SameSubnet value).
Scripts for setting the desired values:
#Set LeaseTimeout (PoSh as Administrator):
(get-cluster).LeaseTimeout = 40000#Set HealthCheckTimeout (PoSh as Administrator):
(get-cluster).HealthCheckTimeout = 60000#Set SameSubnetDelay (PoSh as Administrator):
(get-cluster).SameSubnetDelay = 2000#Set CrossSubnetDelay (PoSh as Administrator):
(get-cluster).CrossSubnetDelay = 4000#Set RouteHistoryLength ONLY IF THRESHOLDS WERE CHANGED (PoSh as Administrator):
(get-cluster).RouteHistoryLength = 40#Set SessionTimeout (TSQL as SYSADMIN):
ALTER AVAILABILITY GROUP MODIFY REPLICA ON '' WITH (SESSION_TIMEOUT = 20); 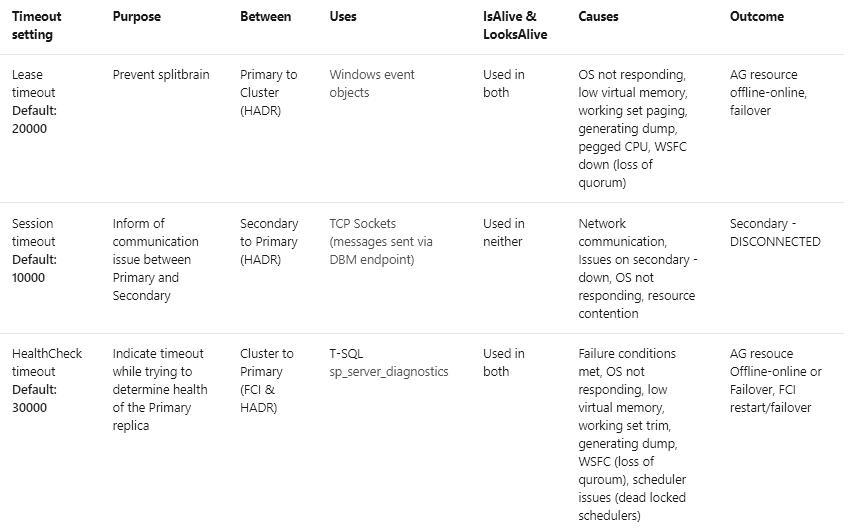
After properly configuring your server and adjusting the Cluster sensitivity, you will see a dramatic decrease in transient connectivity errors and false failover events. Carefully consider the tradeoffs and understand the consequences of using less aggressive monitoring of your SQL Server cluster. Increasing cluster timeout values will increase tolerance of transient network issues but will slow down reactions to hard failures. Increasing timeouts to deal with resource pressure or large geographical latency, will increase the time to recover from hard, or non-recoverable failures as well. While this is acceptable for many applications, it is not ideal in all cases. The correct settings for each deployment will vary and likely take a longer period of fine-tuning to discover. When making changes to any of these values, make them gradually and with consideration of the relationships and dependencies between these values.
Check out a recorded version of Ken’s 2022 PASS Data Community Summit Presentation: