
SQL server deadlock is a common issue that database administrators often encounter, causing significant disruptions in database operations. This article aims to demystify the concept of SQL server deadlocks, particularly focusing on the nuances between traditional deadlocks and parallelism deadlocks. By understanding their causes and learning how to identify and prevent them, you can maintain a more efficient and reliable SQL Server environment.
Parallelism Deadlocks: A Self-Inflicted Stalemate
Imagine, if you will, that you’re in a Western-style showdown with…
… yourself.
And because you’re facing off against yourself, you have the same reflexes, the same aim, and the same sense of timing, so both versions of you shoot… at the same time.
And you both hit in the same general area at the same time.
Needless to say, no one wins.
This is essentially what happens in a type of deadlock known as a “parallelism deadlock” (also known as an “intra-query” deadlock or “exchange” deadlock), where a process splits into different threads to complete a task more efficiently (as is standard for parallelism) and ends up attempting to access the same resource at the same time, even though the resource is locked by… itself. And, naturally, as tends to happen with deadlocks, one process becomes the deadlock victim, but since both “processes” are the same process, the other “process” also becomes a deadlock victim.
Why is this unusual?
Understanding Traditional SQL Server Deadlocks
In case you need a refresher, “traditional” deadlocks involve two processes (let’s call them “Process A” and “Process B”), each competing for a resource (let’s call them “Resource A” and “Resource B”) that the other has locked. For example:
- Process A has a lock on Resource A.
- At the same time, Process B has a lock on Resource B.
- Process A needs to access Resource B, but Process B still has a lock on it.
- Process B needs to access Resource A, but Process A still has a lock on it.
It’s a SQL Server stalemate (a digital Mexican standoff, if you will) that can only be resolved by choosing one process at random (although this can be manipulated by “deadlock priorities,” which is a topic for another day) as the “deadlock victim.” Let’s say, in this example, that Process B gets the short straw. Process B gets killed, freeing up Resource B so that Process A can resume.
Error Message 1205
When this happens, you’ll see a version of Error Message 1205, which says something similar to:
Your transaction (process ID [Process B SPID]) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun your transaction.
Now, remember that (say it with me, folks) it is expected to have deadlocks. And not in the “it’s not a bug, it’s a feature” way, either. Sometimes, deadlocks happen; you can’t necessarily control which processes try to access which resources at which times, so it’s pointless to have the mindset of “I need to make sure NO deadlocks happen EVER!”. The critical thing to remember when tackling deadlocks is to have sufficient error handling in your code so that when a process does get deadlocked, it just automatically reruns, giving it another chance to complete successfully.
Now that that’s out of the way, let’s get back to the topic.
How Do I Know if I Have a Parallelism Deadlock?
In your deadlock report (which you would have if you enabled trace flags 1222 and 1204 on your instance or if you have deadlock monitoring through our VDBA monitoring software), this can be shown in a handful of different ways:
- In your Trace Flag 1222 output, both “keylock hobtid” under the “resource list” section would be the same.
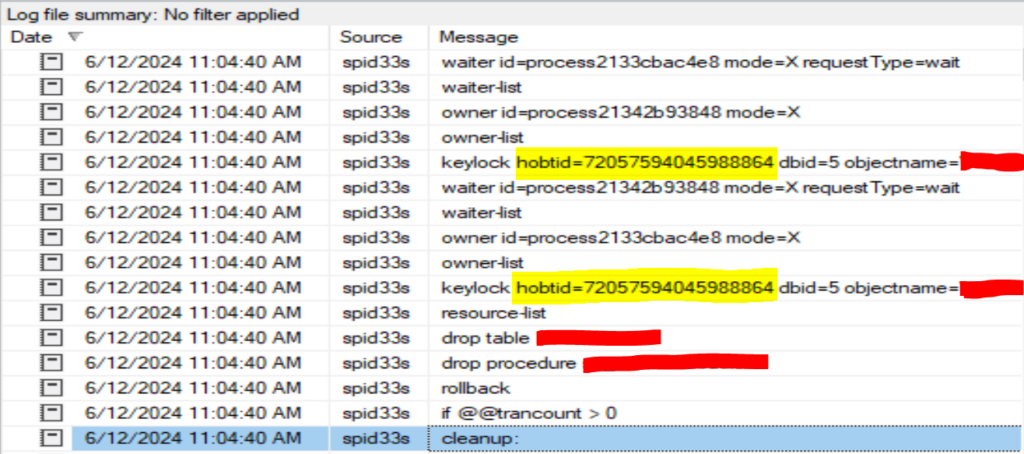
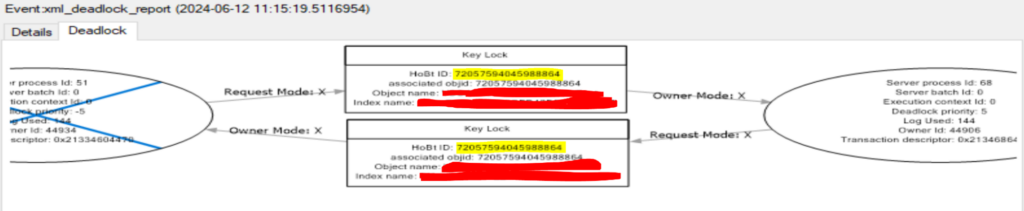
- In the deadlock graph created by the system_health Extended Event session (how to access this graph is out of scope for this post), the HoBT ID (and the AssociatedObjectID, since they’re pretty much interchangeable) would be the same for both processes.
- The HoBT ID for both processes would also be the same in the deadlock report created by our VDBA monitoring software.
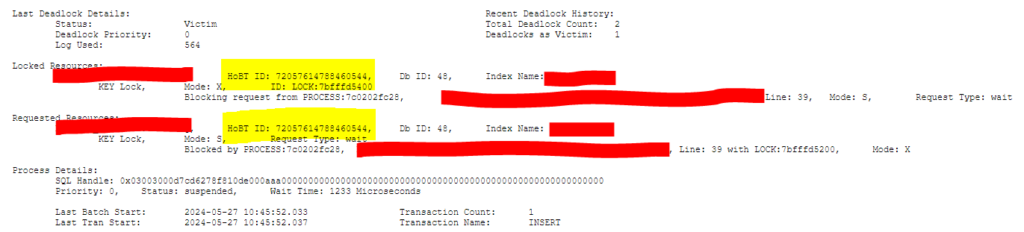
Note, however, that even though most of the details are the same for both processes, right down to the stored procedure being run and the statement where the locks are occurring, the SPIDs are still different. This is how you know it is a parallelized process.
A Side Note: Page-level Parallelized Deadlocks
If you want to get specific and granular (as many DBAs do), I just described a parallelism deadlock at the critical level (note how the screenshots above specify that a keylock had occurred). However, there is another type of parallelism, deadlock, where the deadlock occurs at the page level. Our team has also encountered this, but it is less common since it involves databases with multiple files in a filegroup spread out across different disks. In a page-level parallelized deadlock, the individual threads access the same resources differently, causing what looks more like a traditional deadlock. I might go into more detail about that in a future post, but for now, remember that this is also considered a parallelized deadlock, even though it’s on a larger scale and takes on a different appearance.
What Causes Parallelized Deadlocks?
The short answer: SQL Server.
“Well, duh,” you might be saying, but consider that most deadlocks are caused by spaghetti code, less-than-optimal job timing, insufficient lock and isolation level settings, etc.
This, however (fortunately for your developers), is almost exclusively a SQL Server issue. Similar issues have been patched repeatedly in SPs and CUs since at least SQL Server 2012. However, like many bugs, they always find a way to keep popping up.
How Can I Prevent Parallelized Deadlocks from Occurring?
Fortunately, just because there’s no solid cause for parallelized deadlocks, that doesn’t mean there aren’t ways to work around or even resolve the issue.
You can still implement many of the exact solutions and workarounds for traditional deadlocks, but I want to highlight a couple that are particularly useful in this situation:
- Add a nonclustered index on the fields referenced in the “where” clause of your query
- Disable parallelism at the server level by setting MAXDOP to 1 (not recommended in most cases)
- Disable parallelism at the query level by adding “OPTION (MAXDOP 1)” at the end of the query (a much better option than #2)
- Disable page locks
- Adding patches such as SQL Server 2016 SP1 CU3 to prevent parallelized deadlocks from happening in certain circumstances
Parallelized deadlocks can be a pain, especially given their unpredictable nature. However, our experienced SQL Server staff can help mitigate these pesky deadlocks and put the one-person showdown to rest once and for all. Contact us today!