
What is Collation?
Collation is a set of rules dictating how each group of characters within SQL Server is treated. A list of collations and their definitions can be found using the following query.
SELECT name, description
FROM sys.fn_helpcollations()
WHERE COLLATIONPROPERTY(name, 'CodePage') = 0;
There are two types of collations which will appear in the results of the query listed above. These are SQL collations and Windows Collations.
To further break down collations, they are made up of the following options.
- Prefix: This establishes whether or not it is a SQL Server or Windows Collation.
- SortRules: This establishes the alphabet and language used.
- Code Page: Identifies the code page used by the collation. A code page is used to determine the mapping between a character and its byte representation.
- Case Sensitivity: This establishes whether it is case sensitive or insensitive.
- Accent Sensitivity: This establishes whether it is accent sensitive or insensitive.
- KanatypeSensitve: This establishes whether SQL Server considers the kana characters Hiragana and Katakana to be equal characters or not. By default, SQL Server collations have this set to insensitive.
- Width Sensitivity: This establishes whether SQL Server considers single bit characters equal to double bit characters. By default, SQL Server collations have this set to insensitive.
- BIN: This establishes the binary sort order.
EXAMPLE:
Omitted (Windows Collation)
SQL_ (SQL Server Collation)
EXAMPLE: ‘Latin1_General'(English)
EXAMPLE: ‘CP1251’ (Code page 1251)
EXAMPLES:
‘CI’ (Case Insensitive; A is the same as a; A=a)
‘CS’ (Case Sensitive; A is not the same as a; A!=a)
EXAMPLES:
‘AI’ (Accent Insensitive; a is the same as à; a=à)
‘AS’ (Accent Sensitive; A is not the same as à; a!=à )
EXAMPLES:
Omitted (Kanatype Insensitive)
KS (Kanatype Sensitive)
EXAMPLES:
Omitted (Width Insensitive;A6 is the same as A6; A6=A6 )
WS (Width Sensitive; A6 is not the same as A6; A6!=A6 )
EXAMPLES:
‘BIN’ (binary sort for Unicode Data) or
‘BIN2’ (binary code point comparison sort for Unicode Data)
-
Example: SQL_Latin1_General_CP1_CI_AS
- Prefix: SQL_ – SQL Collation
- Sort Rules: Latin1_General – English
- Code Page: CP1 – Code Page 1252
- Case Sensitivity: Insensitive
- Accent Sensitivity: Sensitive
-
Example: SQL_Ukrainian_CP1251_CI_AS
- Prefix: SQL_ – SQL Collation
- Sort Rules: Ukrainian
- Code Page: Code Page 1251
- Case Sensitivity: Insensitive
- Accent Sensitivity: Sensitive
-
Example: SQL_Latin1_General_CP437_BIN
- Prefix: SQL_ – SQL Collation
- Sort Rules: Latin1_General – English
- Code Page: CP1 – Code Page 437
- BIN: binary sort for Unicode Data
Why is it important?
The most notable answer to this is language. SQL Server is used by a wide variety of people across the world. It is very important to configure SQL Server to accept commands and characters for the language and alphabet needed.
It is also important to set sensitivity levels at a database level correctly as SQL server will treat certain words as different or the same depending on the setting. If case sensitivity is set, ‘Test’ is not the same word as ‘test’. This will result in them being treated separately. If a table set to be case sensitive is queried for the word ‘Test’, only results with that casing would appear. This would also cause issues in queries if proper formatting isn’t followed. This applies to using accents as well if the query is accent sensitive. The following two queries would not be the same because the table names are capitalized differently.
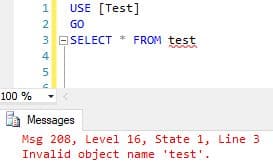
SELECT * FROM Test
SELECT * FROM test
If the table were called “Test,” The second query would actually fail with the error “Invalid object name ‘test’”
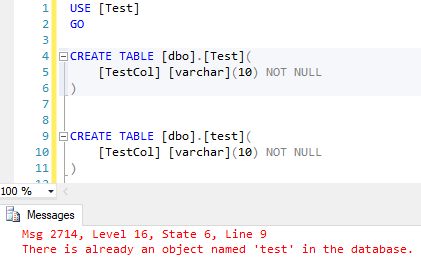
If the database is set to case sensitivity is enabled, multiple tables with the same name can also be created without error. Because of this, it’s even more important to following naming schemas.
It is important to test any collation changes in a test environment before doing any of the previously stated steps. Minor misformatting such as one uncapitalized table name could cause processes that already exist to start failing. It could also cause select statements to return the wrong values.
Using Case Insensitivity:
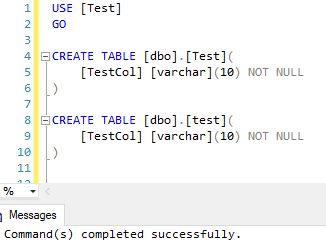
Using Case Sensitivity:
How is it set?
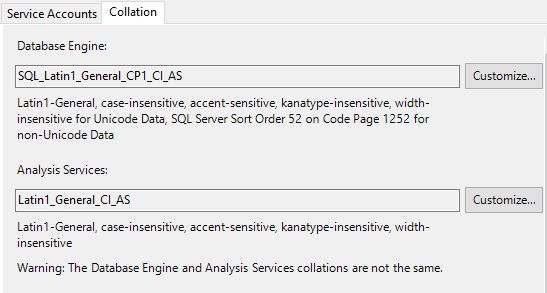
Server Level
This is done during the installation. Consideration should be taken before changing this setting as it is difficult to alter once set. The options chosen here will determine the default database level collation as well.
Database Level
A database can have its own collation separate from the server level. This setting overrides the server level setting. For any columns that currently exist and the collation is not set to “Database Default,“ the change at the database layer does not affect them but any new columns created will be created with the new setting at the database level unless otherwise specified.
The following might need to be dropped and recreated in order to change a database level collation.
- A computed column
- An index
- Distribution statistics, either generated automatically or by the CREATE STATISTICS statement
- A CHECK constraint
- A FOREIGN KEY constraint
Create Database with Collation:
T-SQL:
CREATE DATABASE [Test] ON PRIMARY
( NAME = N'Test', FILENAME = N'D:\DATA\Test.mdf' )
LOG ON
( NAME = N'Test_log', FILENAME = N'L:\Logs\Test_log.ldf')
COLLATE SQL_Latin1_General_CP1_CS_AS
SSMS:
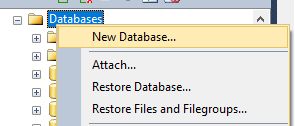
- Right Click Databases and select ‘New Database.’
- Fill in settings as needed.
- Open ‘Options’ tab and select collation.
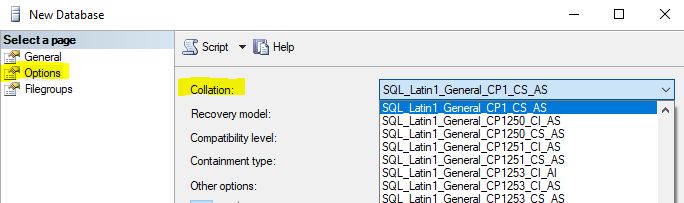
Alter Database Level Collation:
T-SQL:
USE [master]
GO
ALTER DATABASE [AdventureWorks2012] COLLATE SQL_Latin1_General_CP1_CS_AS
GO
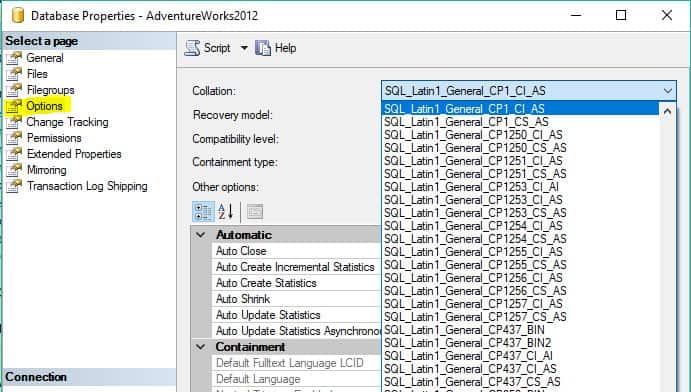
SSMS:
Open properties by right clicking on properties. Once there, access the ‘Options’ tab.
Column Level
Collations can be altered on a column level as well. This can be done during or after table creation. This setting overrides the server and table level collation.
The following might need to be dropped and recreated in order to change a column-level collation.
- A computed column
- An index
- Distribution statistics, either generated automatically or by the CREATE STATISTICS statement
- A CHECK constraint
- A FOREIGN KEY constraint
T-SQL set on creation:
CREATE TABLE dbo.Test
(
TestKey int PRIMARY KEY,
TestCol varchar(10) COLLATE SQL_Latin1_General_CP1_CS_AS NOT NULL
);
GO
T-SQL to alter after:
ALTER TABLE dbo.Test ALTER COLUMN TestCol
varchar(10)COLLATE SQL_Latin1_General_CI_AS NOT NULL;
GO
SSMS:
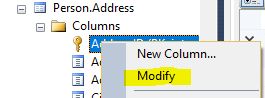
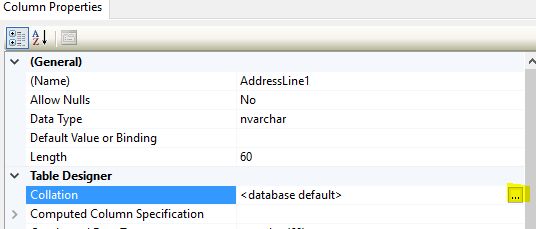
- Locate the table you would like to alter and expand the table and columns.
- Right-click any column and select ‘Modify’.
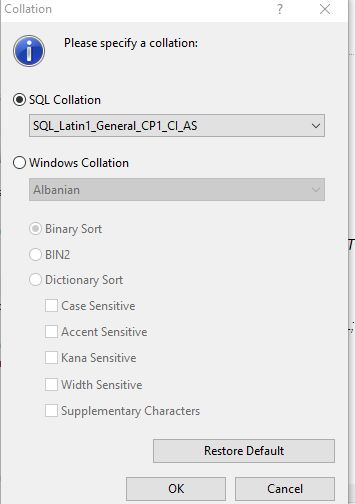
- Locate Collation under Table Designer and click on the ellipsis in that column.
- Select the collation needed.
Temporary Collation T-SQL
Column Level Collation can be temporarily set within a query in the where or order by clause. This is useful when collation specific data is needed. The following example of its use in queries.
--Create Test Table
DECLARE @Test TABLE
(
testChar nvarchar(10)
)
INSERT @Test VALUES ('Test'),('test'),('TEST'),('TeSt')
--Basic Select
SELECT testChar
FROM @Test
--Capital First letter only
SELECT testChar
FROM @Test
where testChar COLLATE SQL_Latin1_General_CP1_CS_AS = 'Test'
--All lower Case
SELECT testChar
FROM @Test
where testChar COLLATE SQL_Latin1_General_CP1_CS_AS = 'test'
--ORDER BY Case
SELECT testChar
FROM @Test
ORDER BY testChar COLLATE SQL_Latin1_General_CP1_CS_AS
Final Thoughts
It is recommended to plan out collation settings ahead to time to prevent the need for changes later on. If changes are needed, this alters how SQL Server reads characters. Because of this, it is important to test these changes before adding them to a production environment. It could result in process failures and incorrect search results.
It is also helpful to plan out processes ahead of time to work on instances that have strict collations set just in case collation changes are needed in the future. This will prevent errors from happening, and it will make the switch go a lot smoother.